Google PhraseRank: indicizzazione per frasi.
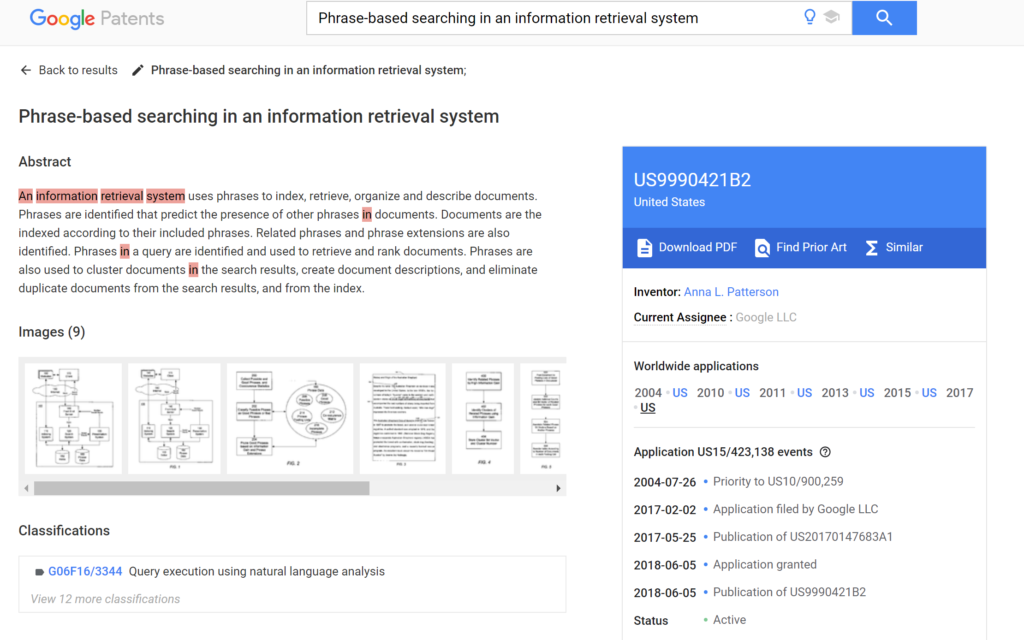
Phrase identification in an information retrieval system I sistemi di IR finora usati dai più grandi motori di ricerca si sono sempre basati sull’acquisizione di contenuti e documenti di testo tramite algoritmi in grado di riconoscere i temi trattati da un documento usando le singole parole contenute: da un documento, eliminate le stopwords, si acquisiscono le parole che …