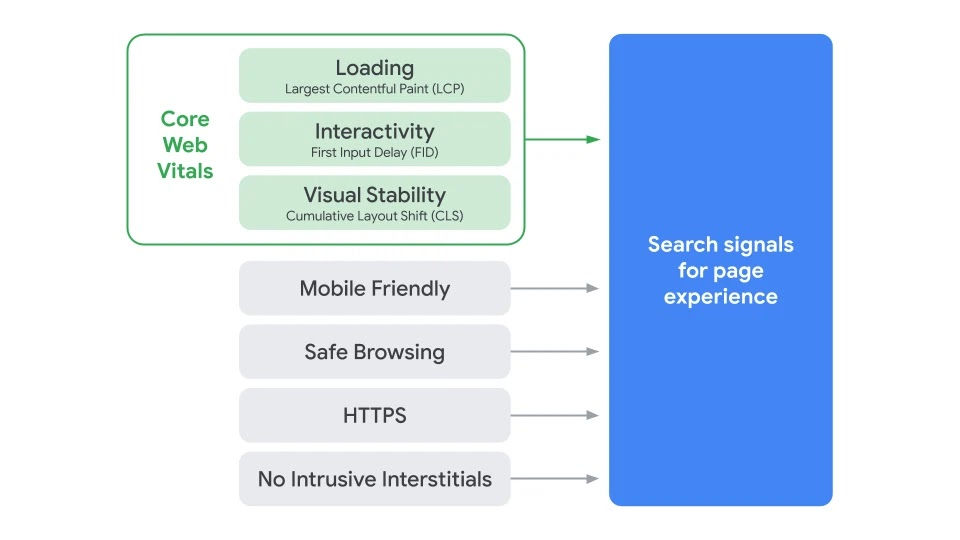
Google Page Experience
Era nell’aria nella community seo internazionale che i nuovi Core Web Vitals diventassero fattore di ranking, ma dalle teorie alla ufficialità il passo è grande. Oggi Google in un articolo del suo blog annuncia “Page Experience Update“, “Evaluating page experience for a better web“, e indica i nuovi Core Web Vitals, presentati ad inizi Maggio …